
Printworks, London
Transformers 3: Building and training a Transformer
Having discussed how attention works and the structure of Transformers we’ll now implement a simple Transformer that translates German text into English. To do this we’ll take the attention mechanism and other network components that Andrej Karpathy developed in nanoGPT for language generation and reuse them to implement a Transformer for language translation. This uses the PyTorch framework. The language translation Transformer’s structure follows the example in François Chollet’s book ‘Deep Learning with Python’ which is written in Keras/TensorFlow. The relatively small scale of the model built here and the data it is trained on means it won’t be able to perfectly translate text, but will be able to generate translations to some extent.
This note covers:
1. Specifying the parameters of the Transformer
2. Processing the text data
3. The structure of the Transformer
4. The implementation of attention
5. The implementation of other Transformer components
6. Putting all the components together to create a Transformer
7. Training
8. Generation of translations
The code described below is available from the repo here. I have written this note and its predecessors to improve my knowledge of this topic. Maybe it is useful for others, but at the same time I am not an expert on this subject and would recommend people consult the two resources it is based on for authoritative discussions of the area.
1. Specifying the parameters of the Transformer
To start we will initialise the model with a Python dataclass (config.py) that specifies the model’s key parameters:
from dataclasses import dataclass
@dataclass
class TransformerConfig:
"""With a dataclass we don't need to write an init function, just specify class attributes and their types"""
vocab_size: int = 15000
dim_embedding: int = 600
dim_inner_layer: int = 2000
n_head: int = 6
batch_size: int = 30
block_size: int = 20
epochs: int = 30
dropout: float = 0.2
bias: bool = False
config = TransformerConfig()
The model has an embedding dimension of 600 and a vocabulary size of 15,000 for each language. At various stages in the Transformer there are inner layers that increase the dimensionality of the vectors describing the words to 2000, giving the model more weights to capture the language structure. Attention is calculated over 6 heads in parallel, which due to how it is implemented involves 100 dimensional query, key and value vectors. During training German text and a corresponding English translation will be input in batches of 30 text-pairs. Both the German text and English translation texts are in blocks of text capped at 20 words\tokens in length. In training we’ll loop through the training data 30 times (30 epochs). 20% dropout is implemented in a number of stages in the network.
2. Processing the text data
To get some text data to train and test the Transformer we download the English-German translation pairs from anki and unzip the file:
$ wget https://www.manythings.org/anki/deu-eng.zip && unzip deu-eng.zip
This produces the text file (deu.txt) which consists of pairs of English and German text, for example:
Bless you. Gesundheit
Buy a gun. Leg dir eine Schusswaffe
We want to convert the words in both the English and German texts into numbers and generate test and training data sets. To do this we process the texts with the Python script text_processing.py. This starts by simplifying the text, processing the pairs to remove punctuation and setting the text to lowercase. [start] and [end] tags are added at the beginning and end of all of the English texts.
import torch
import torch.nn.functional as Fun
from torch.utils.data.dataset import random_split
from collections import Counter
from string import punctuation
import pickle
from config import TransformerConfig
# Initialize configuration
config = TransformerConfig()
# Strip punctuation
def strip_punctuation(s):
"""Function that removes punctuation"""
return str("".join(c for c in s if c not in punctuation))
# Add 0s to the tensor up to the value of the block size
def tensor_pad(x):
"""converts list to tensor and pads to length 20"""
return Fun.pad(torch.tensor(x, dtype=torch.int64), (0, config.block_size), value=0)
def main():
"""This is the function which processes the text to output it in a form used by the model"""
text_file = "deu.txt"
with open(text_file) as language_file:
lines = language_file.read().split("\n")
print("There are " + str(len(lines)) + " lines")
# Split the text file into German and English, setting it to lower case and removing punctuation
# We append a [start] at the beginning of each line of the English text and end it with [end]
text_pairs = []
for i, line in enumerate(lines):
try:
english, german = line.split("\t")[0:2]
english = "[start] " + strip_punctuation(english.lower()) + " [end]"
text_pairs.append([strip_punctuation(german.lower()), english])
except:
print("failed to load line %s" % (i))
We combine all the English texts, and separately combine the German texts, to calculate the distinct words used in each language. We then create a class WordsNumbers which is initiated for each language separately and identifies the most common words in each. It has two methods that are dictionaries allowing the most common 15,000 words in each language to be converted into numbers and the numbers converted back to words. Technically it is 14,999 words as we reserve the 0 token to represent the blank spaces used to pad both English and German texts to get to 20 words/tokens if they have fewer than that. Mapping the texts' words into numbers is the simplest possible approach, more sophisticated encodings based on parts of speech or combinations of words are also possible.
# To get the tokens used in English and German texts we create
# two separate lists and from these create a single German text and a single English text
german_list = [item[0] for item in text_pairs]
english_list = [item[1] for item in text_pairs]
german_text = " ".join(german_list)
english_text = " ".join(english_list)
class WordsNumbers:
"""Class that produces two dictionaries of the most common words from the input text, one of which maps words
to numbers and the other one reverses this mapping numbers to words."""
def __init__(self, text, config):
self.text = text
self.config = config
# Get the tokens
self.tokens_list = list(set(self.text.split()))
# Get the most common tokens
# Subtract -1 as we want to leave one of the 15,000 numbers to code the padding token rather than words. We use 0 for this.
self.tokens_counter = Counter(self.text.split()).most_common(
self.config.vocab_size - 1
)
self.tokens_vocab = [item for item, count in self.tokens_counter]
def to_words(self):
# Converts from the numbers to words
word_dict = {i + 1: token for i, token in enumerate(self.tokens_vocab)}
return word_dict
def to_numbers(self):
# Converts from words to numbers
number_dict = {token: i + 1 for i, token in enumerate(self.tokens_vocab)}
return number_dict
We then apply the dictionaries to encode the English and German texts into numbers. The English translation text is processed into two copies. One that has the [end] token removed which will be input for training and one which has the [start] token removed which is used as the target text the model is trying to predict. The [start] token is used in translation to tell the model to start generating a translation so we need it as an input, but do not need it as an output. Conversely, we want the model to be able to predict when the translation sentence ends so include the [end] token in the target for the model to predict, but we do not use it as an input. Each German and English text is padded with 0s to get to block sizes of 20 tokens. The methods to convert between words and numbers start their numeric count at 1 to keep 0 for the padding. We then split the dataset 80%:20% into training and test datasets respectively.
# Get the German tokens and the English tokens
english_tokens = WordsNumbers(english_text, config)
german_tokens = WordsNumbers(german_text, config)
# Creates dictionaries converting words into numbers
english_numeric = english_tokens.to_numbers()
german_numeric = german_tokens.to_numbers()
# Save the English and German dictionaries
with open("english_dictionary.pkl", "wb") as eng:
pickle.dump(english_numeric, eng)
with open("german_dictionary.pkl", "wb") as ger:
pickle.dump(german_numeric, ger)
# Convert the texts into numbers for the words that are in the 15000 most common words in either language
text_pairs_encoded = [
[
[
german_numeric[element]
for element in pair[0].split()
if element in german_tokens.tokens_vocab
],
[
english_numeric[element]
for element in pair[1].split()
if element in english_tokens.tokens_vocab
],
]
for pair in text_pairs
]
# Split the data between:
# the encoder input in German
# the decoder input in English, where the end token is removed elem[1][:-1]
# english output we are trying to predict which is shifted one token to the right elem[1][1:]
text_pairs_encoded_split = [
(elem[0], elem[1][:-1], elem[1][1:]) for elem in text_pairs_encoded
]
# Pads each bit of text to 20 tokens by adding 0s with tensor_pad and truncating at block size
text_pairs_encoded_padded = [
[
tensor_pad(item1)[: config.block_size],
tensor_pad(item2)[: config.block_size],
tensor_pad(item3)[: config.block_size],
]
for item1, item2, item3 in text_pairs_encoded_split
]
# Calculate how many observations are needed for a 20% test sample
test_len = round(len(text_pairs_encoded_padded) * 0.2)
# Calculate the number of training observations as the residual
train_len = round(len(text_pairs_encoded_padded)) - test_len
# Get the train dataset and the test dataset
train_dataset, test_dataset = random_split(
text_pairs_encoded_padded, [train_len, test_len]
)
# Save the test and training datasets as pickle files
torch.save(train_dataset, "train_dataset.pt")
torch.save(test_dataset, "test_dataset.pt")
# Only run main if this script is run directly
if __name__ == "__main__":
main()
3. The structure of the Transformer
The annotated schematic below, based on the diagram from the original Transformers paper, shows the encoder, decoder and their underlying components. In sections 4 and 5 we discuss these components. In section 6 we use them to implement embedding layers for each language, an encoder, a decoder and combine all of these to create a Transformer.
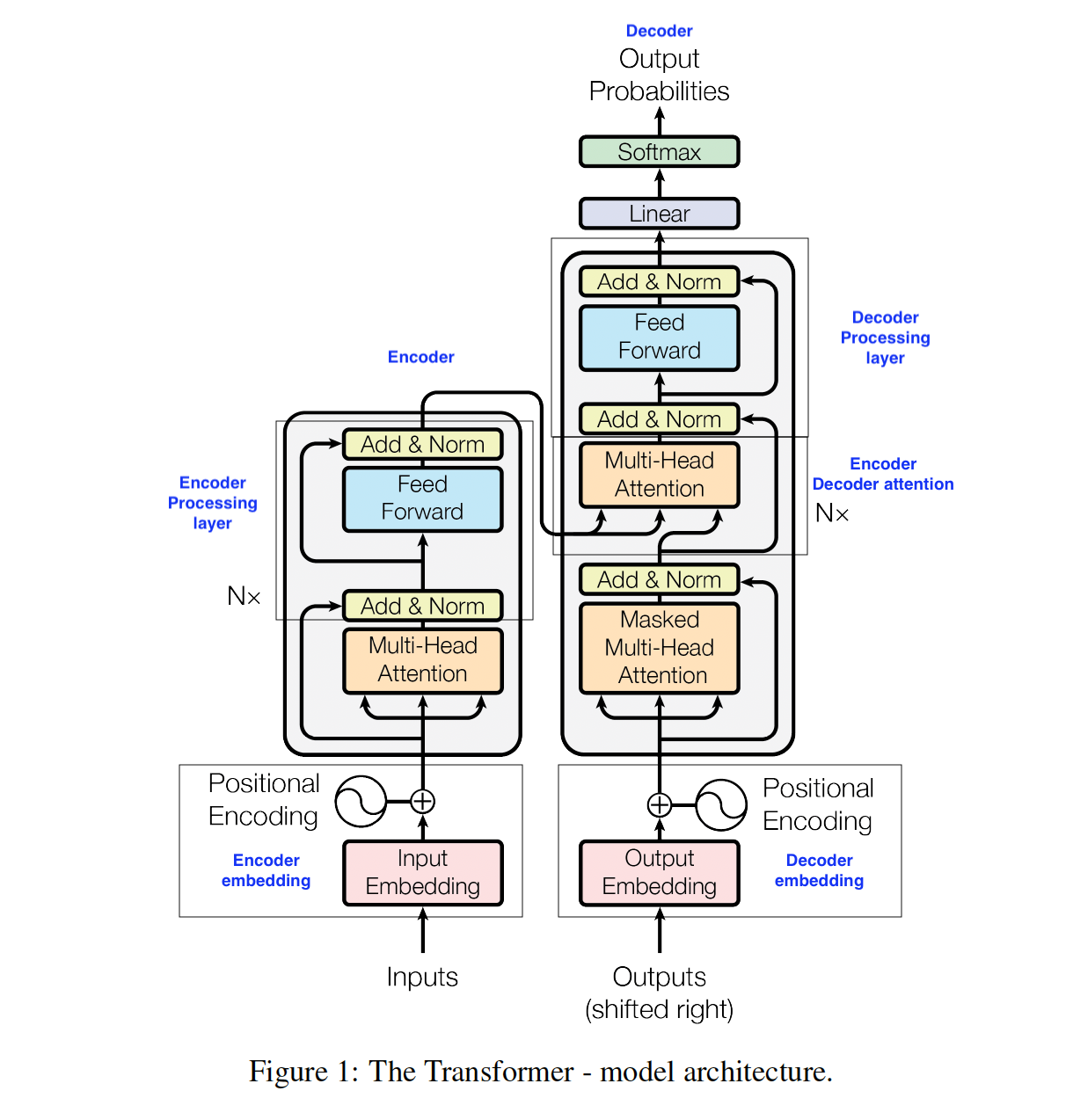 
Original figure is from ‘Attention is All You Need’, Vaswani et al.(2017)

Original figure is from ‘Attention is All You Need’, Vaswani et al.(2017)
Broadly speaking we take the processed German and English texts, embed them into vectors with embedding layers. The embedding vectors from the language we want to translate from (here German) pass into the Encoder layer, where an attention calculation is done on them (Multi-Head attention) and further processing applied (Encoder Processing layer). The embedding vectors from the language we want to translate into (here English) pass into the Decoder layer where a different attention calculation (Masked Multi Head Attention) is applied taking into account that the translation is built one word at a time, based on the previous words of the translation. The results from this are then combined with the outputs of the encoder in another kind of attention calculation (Encoder Decoder Attention). More processing layers (Decoder Processing layer) are applied to the outputs of this calculation and the model then outputs the results of the final layer which has the dimensionality of the vocabulary size we are using (here 15,000).
In our example we have one Transformer layer so N=1 (as shown in the diagram). If we had more Transformer layers, the outputs of the first encoder layer feeds into the next encoder layer, and so on, until the last encoder layer. The output from the last encoder layer then feeds into each of the decoder layers for an attention calculation, where each decoder layer after the first one takes its input from the last encoder layer and the preceding decoder layer.
One element in the diagram missing in our implementation is that there is no softmax layer in our Transformer. This is because the PyTorch cross-entropy metric that we are optimising in training automatically applies a softmax so it does not need to be added to train the model. However, for the translation after training we want the model to output a probability distribution and so apply a softmax layer to the outputs of the trained Transformer there.
4. The implementation of attention
The following code forms part of the Transformer script network_components.py which contains the model components.
Below is the implementation of attention that Andrej Karpathy used in nanoGPT (there are some minor changes to comments and removing some parts not used at this stage as the original nanoGPT was designed for language generation). As with all PyTorch network classes it inherits from the nn.Module class and sets up the components that are used to construct the network when it is initiated. The forward method then details what happens when the data is input into the network layers that are specified in the class. The different attention classes used in the Transformer are variants of this attention class.
In this post we keep them distinct so that all of the network’s working is explicit, but in the repo the code shown below has been refactored with the other two attention classes (EncoderDecoderAttention and MaskedMultiHeadAttention) inheriting from the MultiHeadAttention class.
import torch
import torch.nn.functional as Fun
from torch import nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
# Checks that the dimension of the embedding vector can be divided by the number of heads
assert config.dim_embedding % config.n_head == 0
# set embedding and head sizes
self.n_head = config.n_head
self.dim_embedding = config.dim_embedding
# nn.Linear applies a linear y=Ax+b transformation to the input
# the input dimension is the first argument
# the output dimension is the second argument
# the last argument is the b (bias) term
# Sets up a layer that increases the dimensionality of the embedding 3x to calculate the query, key and value vectors
self.c_attn = nn.Linear(
config.dim_embedding, 3 * config.dim_embedding, bias=config.bias
)
# output projection
self.c_proj = nn.Linear(
config.dim_embedding, config.dim_embedding, bias=config.bias
)
# regularisation
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.dropout = config.dropout
# Uses a faster implementation of attention if scaled_dot_product_attention available in module torch.nn.functional
# (which it is from PyTorch >= 2.0)
self.flash = hasattr(torch.nn.functional, "scaled_dot_product_attention")
if not self.flash:
print(
"WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0"
)
def forward(self, x):
# Get the values of the batch size, block size and embedding dimensionality
(
B,
T,
C,
) = x.size()
# calculate query, key, values vectors from the input embedding vectors
q, k, v = self.c_attn(x).split(self.dim_embedding, dim=2)
# split k, q and v down to batch_size, number_heads, block size, dimension_embedding/number_heads
k = k.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
# self.training is set to true when model.train() is initiated
y = torch.nn.functional.scaled_dot_product_attention(
q,
k,
v,
attn_mask=None,
dropout_p=self.dropout if self.training else 0,
is_causal=False,
)
else:
# manual implementation of attention
# Calculate the inner product of the q and k vectors and normalise by square root of length of key vectors
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# Apply the softmax layer so that everything sums to 1
att = Fun.softmax(att, dim=-1)
# Apply dropout
att = self.attn_dropout(att)
# Multiply the attention results by the value vectors
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# Change the shape of the tensor back to B, T, C re-assembling the head outputs side by side
y = y.transpose(1, 2).contiguous().view(B, T, C)
# output projection and droput
y = self.resid_dropout(self.c_proj(y))
return y
The code below shows the creation of key, query and value vectors from the embeddings, which is implemented by passing the embedding vectors into
c_attn(x) which generates these three types of vectors. These vectors are then split again by the number of heads to perform the attention calculation.
The original vectors used to produce the query, key and value vectors have 600 dimensions and there are 6 heads, so this produces 6 sets of query, key and value vectors of 100 dimensions each, for 6 different sets of parallel attention calculations.
q, k, v = self.c_attn(x).split(self.dim_embedding, dim=2)
# split k, q and v down to batch_size, number_heads, block size, dimension_embedding/number_heads
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs
The method contains an optimised attention mechanism to process these collections of vectors called scaled_dot_product_attention. Here we have is_causal=False as this is the encoder side and in
translation we assume that the Transformer has access to the full German text before starting translation. This means that attention is calculated between all the vectors that represent the words in a line of German text.
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=False)
By contrast on the decoder side in the Masked Multi-Head Attention layer, as we will cover later, is_causal=True (and attention calculated using previous words only) when processing the English translations as in generating the prediction this is done autoregressively with the prediction for the next word of the translation based on the previous predicted words. In the training data therefore, to predict the n’th word of the translation the Transformer is given access to the n-1 English words before. For the very first translated word the [start] token is used as the ‘word 0’ to initialise the translation.
If scaled_dot_product_attention is not available then the class also implements attention
directly in Python. This illustrates more explicitly the stages in calculating attention.
The multiplication of the query and the transposed key matrices of associated vectors. The result of this being normalised by the square root of the key
vectors' dimensionality:
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
The application of the softmax layer:
att = Fun.softmax(att, dim=-1)
The multiplication of the attention weights by the values vectors:
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
The concatenation of the head outputs, creates vectors of the standard embedding dimension, which are then transformed by another set of weights into a vector of the same dimensionality. In the Karpathy implementation he then adds a dropout layer.
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
We start with the data entering the Transformer after the embedding layers being a tensor of size (B, T, C), where B is batch size, T is block size and C the embedding dimensionality. In an attention calculation this then gets converted to 3 sets of key, query and value vectors of size (B, T, C) and then split again into a tensors of size (B, nh, T, hs). Where C is split into the number of separate heads nh and the size of the vectors hs they process. At the end of the attention calculation the results from the different heads are combined and we end back at (B, T, C). At the end of the model we scale C back up to the size of the vocabulary we are translating to.
To give a direct example, in our model this means that the tensors representing a batch start off having dimensions (30,20,600). In the attention calculation the embedding dimension of this is then scaled up 3x by ac_attn then split into 3 sets of query, key and value vectors of dimensions (30,20,600). These are then split on the embedding dimension again into 6 giving (30, 6, 20, 100) for 6 separate attention calculations on 100 dimensional vectors. The results of the 6 head calculations are then combined and we go back to (30,20,600). In the final layer of the Transformer we convert back to the dimensionality of the vocabulary layer and get to (30,20,15000).
5. The implementation of other Transformer components
The other Transformer components that are implemented are:
1. The Embedding layers
2. Processing layers
3. Masked Multi-Head Attention layers
4. Encoder Decoder Attention layers
5.1 The Embedding layers
The embedding class below takes in the encoded text and passes it to the word embedding layer (wte) and the position embedding layer (wtp). These map the word and its position in the text into two vectors of the chosen embedding dimensionality. The two vectors are then added together encoding both the word and its position in the text in a single vector. This is done for all of the 20 words/tokens in a piece of text fed into the network and their relative position in the text. There are two distinct embedding layers at the beginning of the Transformer to separately embed the English and German texts into vectors.
class Embedding(nn.Module):
def __init__(self, config):
super().__init__()
# Creates the text embedding and the position embedding
# nn.Embedding automatically does the one hot encoding so this
# does not need to be created directly
self.config = config
self.wte = nn.Embedding(config.vocab_size, config.dim_embedding)
self.wtp = nn.Embedding(config.block_size, config.dim_embedding)
def forward(self, x):
# Generates the word embedding from the text
x = self.wte(x)
# Generates the position embedding by passing the position ids representing word position to the position embedding layer
position_ids = (
torch.arange(self.config.block_size).unsqueeze(0).repeat(x.size(0), 1)
)
position_embeddings = self.wtp(position_ids)
# Add the two embeddings
x = x + position_embeddings
return x
5.2 Processing layers
The LayerNorm class applies layer normalisation, calculating the mean and standard deviation across the batch for each word position in the text and elements of the vector per word and then subtracting these means and dividing by the standard deviation from the corresponding elements across the batch.
class LayerNorm(nn.Module):
"""LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return Fun.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
A series of layers that implement layer normalisation, a dense layer again and then a dense layer with a skip connection and then layer normalisation. We label this pattern of layers which appears in both the decoder and encoder as processing layers.
class ProcessingLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.denselayer1 = nn.Linear(config.dim_embedding, config.dim_inner_layer)
self.denselayer2 = nn.Linear(config.dim_inner_layer, config.dim_embedding)
self.layernorm1 = LayerNorm(config.dim_embedding, bias=config.bias)
self.layernorm2 = LayerNorm(config.dim_embedding, bias=config.bias)
def forward(self, x):
# A layer norm and then two dense layers\n",
x_in = self.layernorm1(x)
x = self.denselayer1(x_in)
x = self.denselayer2(x) + x_in
x = self.layernorm2(x)
return x
5.3 Masked Multi-Head Attention layers
As discussed, the English translation is generated one word at a time, in training we assume that attention is only calculated between the words prior to given a word i.e. words that would be already known in producing the translation. To do this we apply a mask to the attention calculation to restrict the calculation of attention in this way.
There is a class that implements masked multi-head attention for the text in the language we want to translate into. This forms the first attention layer of the decoder processing the English text translations during training and the generated English text translations during translation. In the scaled_dot_product_attention implementation of attention it is calculated for a given word using only preceding words and is implemented by including an is_causal=Truein the function.
In the alternative direct implementation of attention the mask is applied directly to the attention calculation in the line below:
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
where the bias is defined in the term:
self.register_buffer(
"bias",
torch.tril(torch.ones(config.block_size, config.block_size)).view(
1, 1, config.block_size, config.block_size
),
)
The register_buffer creates a tensor called “bias” that will not be updated during training, unlike the model weights. The bias term has the form of a lower triangular matrix. For example, if the block size is three words then the register buffer has size [1,1,3,3] and looks like this:
tensor([[[[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]]]])
In the masked_fill T is the block_size and the upper triangular elements that are 0 are set to -inf in the mask. When the mask is applied to the attention calculation the lower triangular elements corresponds to the attention of the first word being based on the word itself, the attention of the second word being based on the first and second word etc etc maintaining the causality that attention is only calculated between a given word and its predecessors (but not future words). As the next layer is a softmax layer which has exponential functions, exp^0 = 1, so a 0 as an input would still give positive values for the upper diagonal elements, but as the input tends to -inf the exponentials tend to 0 so setting 0 elements to -inf removes them from the output post softmax layer.
class MaskedMultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
# Checks that the dimension of the embedding vector can be divided by the number of heads
assert config.dim_embedding % config.n_head == 0
# set embedding and head size
self.n_head = config.n_head
self.dim_embedding = config.dim_embedding
self.c_attn = nn.Linear(
config.dim_embedding, 3 * config.dim_embedding, bias=config.bias
)
# output projection
self.c_proj = nn.Linear(
config.dim_embedding, config.dim_embedding, bias=config.bias
)
# regularisation
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.dropout = config.dropout
# Uses a faster implementation of attention if scaled_dot_product_attention available in module torch.nn.functional
# (which it is from PyTorch >= 2.0)
self.flash = hasattr(torch.nn.functional, "scaled_dot_product_attention")
if not self.flash:
print(
"WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0"
)
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer(
"bias",
torch.tril(torch.ones(config.block_size, config.block_size)).view(
1, 1, config.block_size, config.block_size
),
)
def forward(self, x):
# Get the values of the batch size, block size and embedding dimensionality
(
B,
T,
C,
) = x.size()
# calculate query, key, values vectors from the input embedding vectors
q, k, v = self.c_attn(x).split(self.dim_embedding, dim=2)
# split k, q and v down to batch_size, number_heads, block size, dimension_embedding/number_heads
k = k.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(
q,
k,
v,
attn_mask=None,
dropout_p=self.dropout if self.training else 0,
is_causal=True,
)
else:
# manual implementation of attention
# Calculate the inner product of the q and k vectors and normalise by square root of length of key vectors
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# Calculate the masked attention
att.masked_fill(self.bias[:, :, :T, :T] == 0, float("-inf"))
# Apply the softmax layer so that everything sums to 1
att = Fun.softmax(att, dim=-1)
# Apply dropout
att = self.attn_dropout(att)
# Multiply the attention results by the value vectors
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# Change the shape of the tensor back to B, T, C re-assembling the head outputs side by side
y = y.transpose(1, 2).contiguous().view(B, T, C)
# output projection and dropout
y = self.resid_dropout(self.c_proj(y))
return y
5.4 Encoder Decoder Attention layer
The second attention layer in the decoder (the Encoder Decoder Attention layer) has two inputs: the output from the encoder and the normalised output from the decoder’s masked attention layer. In the encoder decoder attention layer the encoder output is transformed into key and value vectors. These vectors are then combined in an attention calculation (without masking) with the query vectors created from the vectors output from the decoder’s previous layer. To do this we have two separate layers one which takes the encoder output and one which takes the decoder input.
# Sets up two separate layers, one to calculate the key and value vector from the output of the encoder
# The scaling up by two in c_attn_en is to produce the key and value vectors from the output of the encoder
self.c_attn_en = nn.Linear(
config.dim_embedding, 2 * config.dim_embedding, bias=config.bias
)
# Sets up a layer to produce the query vector from the preceding layer in the decoder
self.c_attn = nn.Linear(
config.dim_embedding, config.dim_embedding, bias=config.bias
)
As we want to generate a query and value vectors (and not also query vectors) from the encoder, in comparison with the previous attention calculations, we scale up by two in c_attn_en rather than three and do not scale up at all with c_attn as we only need to produce value vectors.
class EncoderDecoderAttention(nn.Module):
def __init__(self, config):
super().__init__()
# Checks that the dimension of the embedding vector can be divided by the number of heads
assert config.dim_embedding % config.n_head == 0
# set embedding and head sizes
self.n_head = config.n_head
self.dim_embedding = config.dim_embedding
# Sets up two separate layers, one to calculate the key and value vector from the output of the encoder
# The scaling up by two to produce the key and value vectors from the output of the encoder
self.c_attn_en = nn.Linear(
config.dim_embedding, 2 * config.dim_embedding, bias=config.bias
)
# Sets up a layer to produce the query vector from the preceding layer in the decoder
self.c_attn = nn.Linear(
config.dim_embedding, config.dim_embedding, bias=config.bias
)
# output projection
self.c_proj = nn.Linear(
config.dim_embedding, config.dim_embedding, bias=config.bias
)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.dropout = config.dropout
# Uses a faster implementation of attention if scaled_dot_product_attention available in module torch.nn.functional
# (which it is from PyTorch >= 2.0)
self.flash = hasattr(torch.nn.functional, "scaled_dot_product_attention")
if not self.flash:
print(
"WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0"
)
def forward(self, x, e):
# Get the values of the batch size, block size and embedding dimensionality
(
B,
T,
C,
) = e.size()
# calculate the key and value vectors from the output of the encoder
k, v = self.c_attn_en(e).split(self.dim_embedding, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
# calculate the query vectors from the output of the previous decoder layers
q = self.c_attn(x)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(
1, 2
) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(
q,
k,
v,
attn_mask=None,
dropout_p=self.dropout if self.training else 0,
is_causal=False,
)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = Fun.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# Change the shape of the tensor back to B, T, C re-assembling the head outputs side by side
y = y.transpose(1, 2).contiguous().view(B, T, C)
# output projection and dropout
y = self.resid_dropout(self.c_proj(y))
return y
6. Putting all the components together to create a Transformer
We now use all of these components to create an encoder layer and a decoder layer. These are then combined together, with an embedding layer for each, into a single Transformer class which we will initialise and then train. In the repo this has been refactored into two files: one for the encoder and decoder encoder_decoder.py and the one for the Transformer Transformer.py, but here we keep parts together in Transformer.py.
import torch
import torch.nn.functional as Fun
from torch import nn
import math
import network_components as nc
from config import TransformerConfig
# Initialize configuration
config = TransformerConfig()
# The Encoder class
class Encoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# Create an attention mechanism layer for the encoder
self.attention_encoder = nc.MultiHeadAttention(config)
# Set up a processing layer
self.encoder_processing_layer = nc.ProcessingLayer(config)
def forward(self, x):
# Apply the attention mechanism and add the input
x = self.attention_encoder(x) + x
# apply layer norm, two dense layers and a layer norm again
x = self.encoder_processing_layer(x)
return x
# The Decoder class
class Decoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# Create an attention mechanism layer for the decoder
self.masked_attention = nc.MaskedMultiHeadAttention(config)
# Create a layernorm layer
self.layernorm = nc.LayerNorm(config.dim_embedding, bias=config.bias)
# Create the encoder decoder attention layer
self.encoder_decoder_attn = nc.EncoderDecoderAttention(config)
# Set up a processing layer for the decoder
self.decoder_processing_layer = nc.ProcessingLayer(config)
def forward(self, x, y):
# Apply the masked attention mechanism and add the input
y = self.masked_attention(y) + y
# # Apply layer normalisation
y = self.layernorm(y)
# Take the output from the encoder and last layer of decoder and calculate attention again then add the input
y = self.encoder_decoder_attn(y, x) + y
# apply layer norm, two dense layers and a layer norm again
y = self.decoder_processing_layer(y)
return y
# The Transformers class
class Transformer(nn.Module):
def __init__(self, config):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
# Create an embedding layer that embeds the text we want to translate from before it passes to the encoder
self.encoder_embed = nc.Embedding(config)
# Create an embedding layer that embeds the text we want to translate into before it passes to the decoder
self.decoder_embed = nc.Embedding(config)
# Create both the encoder and the decoder layers
self.encoder = Encoder(config)
self.decoder = Decoder(config)
# Create the final layer which maps the model's embedding dimension back to the vocab size
self.final_layer = nn.Linear(config.dim_embedding, config.vocab_size)
def forward(self, x, y):
# Embed the text in the language we want to translate from
x = self.encoder_embed(x)
# Embed the text in the language we want to translate into
y = self.decoder_embed(y)
# Pass the language we want to translate from into the encoder
encoder_out = self.encoder(x)
# Take the output from the encoder and translated text and pass to the decoder
y = self.decoder(encoder_out, y)
# Map the embedding dimension back to the vocabulary size
y = self.final_layer(y)
return y
7. Training
The code below is from the python script train.py which trains the model for 30 epochs. It updates the model weights to minimise the cross-entropy between the predicted translations and the actual translations. In evaluating the metric the 0 padding tokens are ignored. The loss on the training data is output to the screen from batches at regular intervals during each epoch of training. The average loss on the test dataset is computed at the end of each epoch. The model uses an Adam optimiser.
Starting training a new model from scratch is run with:
$ python train.py "new_model"
At the end of each epoch the model and optimizer state are saved to a file indexed by the epoch number. If the training is stopped and one wants to resume from a saved model, then the following format is used (here the model passed to commence training is that saved after the 11th epoch).
$ python train.py model_post_11
Training the model using scaled_dot_product_attention for 30 epochs on a Mac Air M2 with 24 GB RAM doing other things took about 7.5 days.
I also wanted to see the direct implementation of attention at work, but at least with the default Adam settings and the current dataset it did not
converge to meaningful results. However, a two layer version of the direct implementation based on 300 dimensional embeddings and 3 headed attention calculations did produce results, although not obviously better than the version shown here. This version of the Transformer is saved to the repo as Transformer_two_layer.py and can be swapped over to replace the version shown above.
import torch
from torch.utils.data import DataLoader
from torch.utils.data.dataset import random_split
from torch.utils.tensorboard import SummaryWriter
import torch.nn.functional as Fun
from torch import nn
import torch.optim as optim
import sys
import Transformer as Tr
from config import TransformerConfig
# Initialize configuration
config = TransformerConfig()
# Initialize model
model = Tr.Transformer(config)
writer = SummaryWriter()
# Import the training and test datasets and convert them into data loaders
train_dataset = torch.load("train_dataset.pt")
test_dataset = torch.load("test_dataset.pt")
train_dataloader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=config.batch_size, shuffle=True)
# Allow gradients to be computed
torch.set_grad_enabled(True)
# Use the Adam optimizer
optimizer = optim.Adam(model.parameters())
def save_checkpoint(model, optimizer, save_path, epoch):
"""function to save checkpoints on the model weights, the optimiser state and epoch"""
torch.save(
{
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch,
},
save_path,
)
# If a "new_model is being created don't load anything, but if saved model is input load the model and the optimizer state and the last epoch value
if sys.argv[1] == "new_model":
epoch_start = 0
elif sys.argv[1] is not None:
state = torch.load(sys.argv[1])
model.load_state_dict(state["model_state_dict"])
optimizer.load_state_dict(state["optimizer_state_dict"])
epoch_start = state["epoch"]
# The training loop (The + 1 is to get the numbers we want from range)
for epoch in range(epoch_start + 1, config.epochs + 1):
# Set the model to training mode
model.train()
for i, (german, english, output) in enumerate(train_dataloader):
# clear any existing gradients before running a new batch
optimizer.zero_grad()
# Generates a predicted translation
yhat = model(german, english)
# Calculates the cross entropy between the prediction and the target, ignoring the 0s
loss = Fun.cross_entropy(
yhat.view(-1, yhat.size(-1)), output.view(-1), ignore_index=0
)
# write the loss
writer.add_scalar("Loss/train", loss, epoch)
# computes the grad of how the loss changes as the weight changes
loss.backward()
# update the weights
optimizer.step()
# print how the training is doing at regular stages during the epoch
if i % 400 == 0:
print(f"Epoch: {epoch}, Iteration: {i}, Loss: {loss.item()}")
writer.flush()
# Save the model and optimizer
path_to_save = "model_post_" + str(epoch)
save_checkpoint(model, optimizer, path_to_save, epoch)
# Compute average loss on the test set
model.eval() # Set the model to evaluation mode turning off dropout
val_loss = 0.0
with torch.no_grad(): # No gradient computation for validation
for german_test, english_test, output_test in test_dataloader:
yhat = model(german_test, english_test)
loss = Fun.cross_entropy(
yhat.view(-1, yhat.size(-1)), output_test.view(-1), ignore_index=0
)
val_loss += loss.item()
avg_val_loss = val_loss / len(test_dataloader)
writer.add_scalar("Loss/test", avg_val_loss, epoch)
print(f"Epoch: {epoch}, Avg_val_loss: {avg_val_loss}")
8. Generation of translations
The script below translate.py generates translations. It imports the test dataset converting it to a dataloader and the two dictionaries that map the English and German words to numbers. It imports the saved trained model that is identified in the first argument of the script (here it is assumed to be saved in the same directory) and a sentence to translate as the second argument e.g.:
$ python translate.py model_post_30 "das wetter ist gut"
If no text to translate is provided as a second argument, the model loops through the test data set generating translations.
import torch
import torch.nn.functional as Fun
from torch import nn
import torch.optim as optim
from torch.utils.data import DataLoader
import pickle
import sys
import text_processing as text_pro
import Transformer as Tr
# Load the english and german dictionaries
with open("german_dictionary.pkl", "rb") as file_ger:
# Load the pickled object
german_tokens = pickle.load(file_ger)
with open("english_dictionary.pkl", "rb") as file_en:
# Load the pickled object
english_tokens = pickle.load(file_en)
# Reverse the dictionaries to go from the numbers back to the words
# This is used previously in text processing consider refactoring
decode_to_english = {v: k for k, v in english_tokens.items()}
decode_to_german = {v: k for k, v in german_tokens.items()}
# Functions to convert the sentences back into words from numbers
def source_vectorization(x):
"""Converts the German words into numbers"""
return [
german_tokens[element]
for element in x.split()
if element in german_tokens.keys()
]
def target_vectorization(x):
"""Converts the English words into numbers"""
return [
english_tokens[element]
for element in x.split()
if element in english_tokens.keys()
]
# Load the test dataset and convert into a data loader of batch size 1
test_dataset = torch.load("test_dataset.pt")
test_dataloader = DataLoader(test_dataset, batch_size=1 , shuffle=True)
# Set up the Transformer and load its configuration
model_predict = Tr.Transformer(config)
# Take the model that the script is going to use to translate from as the first argument in the command line
model = sys.argv[1]
state = torch.load(model)
# Loads the model
model_predict.load_state_dict(state["model_state_dict"])
The section below generates the translations. It takes the sentence we want to translate and then:
-
Converts that text into integers using the coding developed in the text processing phase, adding any 0 padding needed to get to 20 tokens.
-
Adds an extra dimension with the unsqueeze(0) so that the model which is trained on batches of 30, can read a single sentence rather than needing a batched input of multiple texts i.e. it is effectively creating a dummy batch dimension for the sentence so the model can read the sentence as if it were in a batch.
-
The model then generates the translation one token at a time. It starts with the text we want the trained model to translate (converted into numbers) and a blank translation sentence consisting of the number representing the [start] token and then the 19 0s which forms the start of the translation.
-
The model takes these two inputs and generates a probability distribution for its prediction of the first word of the translation. It then samples from the probability distribution i.e. the word with highest predicted probability is most likely to be chosen.
-
The number representing the predicted word is then added to the decoded sentence as the next word after [start], so it is now the numbers representing 2 words and 18 0s.
-
The original sentence and the updated translation sentence is then input into the trained model to generate the second word of the translation etc etc.
-
All of the above is in terms of the numbers that represent the words in both languages. As the numeric translation sentence is built it gets mapped back from the numbers to the English words. This continues until the model predicts the token [end] and the translation process stops.
# Sets the model state to evaluate
model_predict.eval()
def prediction(x, y):
"""This gives the probability distribution over English words for a given German translation"""
logits = model_predict(x, y)
logits = logits.squeeze(0) # Will remove the first dimension if it is set to 0
# The dim = -1 applies softmax over the last dimension of the tensor
return Fun.softmax(logits, dim=-1)
def decode_sequence(input_sentence):
"""This function generates the translation"""
# Unsqueezing adds an extra dimension so that the model which was trained on batches can read single sentences
tokenized_input_sentence = text_pro.tensor_pad(source_vectorization(input_sentence))[
: config.block_size
].unsqueeze(0)
# initalises the decoded sentence with [start]
decoded_sentence = "[start]"
# Loop through the sentence word by word
for i in range(0, config.block_size):
tokenized_target_sentence = text_pro.tensor_pad(target_vectorization(decoded_sentence))[
: config.block_size
].unsqueeze(0)
# Generate predictions
predictions = prediction(tokenized_input_sentence, tokenized_target_sentence)
# The first index in the predictions tensor is the word's position in the sentence
# the second index is the predicted word
# The .item() extracts the tensor index from the tensor
sampled_token_index = torch.multinomial(predictions[i, :], num_samples=1).item()
# Gets the word corresponding to the index
sampled_token = decode_to_english[sampled_token_index]
# Appends the word to the predicted translation to date
decoded_sentence += " " + sampled_token
# If the predicted token is [end] stop
if sampled_token == "[end]":
break
return decoded_sentence
def trans(x, lan):
"""This is a function to translate the English and German text from the number-word dictionaries that we have of them"""
results = ""
for elem in x:
if elem != 0:
if lan == "ger":
results = results + " " + decode_to_german[elem]
if lan == "eng":
results = results + " " + decode_to_english[elem]
return results
# Style class to format the print statements
class style:
BOLD = "\033[1m"
UNDERLINE = "\033[4m"
END = "\033[0m"
# If there are no arguments other than the script itself and the model evaluate the test sample at regular intervals
if len(sys.argv)==2:
# Looking at selected sentences from the test data
for i, elem in enumerate(test_dataloader):
if i % 3400 == 0:
print(style.BOLD + "Orginal" + style.END)
german = trans(elem[0].tolist()[0], "ger")
print(german)
print(style.BOLD + "Translation" + style.END)
print(trans(elem[1].tolist()[0], "eng"))
print(style.BOLD + "Machine Translation" + style.END)
print(decode_sequence(german))
print("\n")
# If there is also an additional argument i.e. a sentence to translate, translate the sentence and then exit
elif len(sys.argv) == 3:
print(decode_sequence(sys.argv[2]))
sys.exit()
Looking at a sample of random test German sentences fed in we obtain the following machine translations from the Transformer compared to the English translation in the test data (This is based on the model at epoch 26) :
**Orginal**
wann hast du das geräusch gehört
**Translation**
[start] when did you hear the sound
**Machine Translation**
[start] when did you hear the noise [end]
**Orginal**
schenke dem keine beachtung
**Translation**
[start] dont pay any attention to that
**Machine Translation**
[start] pay attention to disobeyed in [end]
**Orginal**
ich habe die bücher die ich mir aus der bibliothek ausgeliehen hatte zurückgebracht und mir ein paar neue ausgeliehen
**Translation**
[start] i returned the books i borrowed from the library and i borrowed some new ones
**Machine Translation**
[start] ive wears a few books that for me [end]
**Orginal**
wie oft essen sie schokolade
**Translation**
[start] how often do you eat chocolate
**Machine Translation**
[start] how often eat chocolate [end]
**Orginal**
ich kann ein geheimnis bewahren
**Translation**
[start] i can keep a secret
**Machine Translation**
[start] i can drive a secret [end]
**Orginal**
möchtest du wissen wer das gemacht hat
**Translation**
[start] do you want to know who did this
**Machine Translation**
[start] do you want to know who was doing that [end]
**Orginal**
ich möchte mit deiner mutter sprechen
**Translation**
[start] i want to talk to your mother
**Machine Translation**
[start] i want to know with your mother [end]
Two of the translations are essentially correct, but for slight differences in emphasis which will not matter in many cases. One is understandable, but has a grammatical error. Four have several of the words right, but due to some mistakes do not have a clear meaning.
Trying it on an example of one of the standard challenges for English speakers learning German, the fact that meanings can change with variations of the definite article, it translates “ich renne in den park (I run into the park)” as “i disappear into the park”, but “ich renne in dem park” comes back as “i’m leaving the park”, when it should be “i run in the park” (The switch from der to dem changes the meaning, but the network hasn’t perfectly translated either). Looking at some variations: it gets the noun and pronoun broadly right, presumably as they are more common in the training data, but the verb and preposition less so.
| Original | Translation | Machine translation |
|---|---|---|
| ich renne in den park | i run into the park | i disappear into the park |
| du rennst in den park | you run into the park | youre sober in the park |
| er rennt in den park | er runs into the park | he gets up in the park |
| sie rennt in den park | she/they/you(polite) runs/run into the park | she runs into the park |
| wir rennen in den park | we run into the park | we run over the park |
On the basis of this short and not particulary scientfic evaluation the model has clearly developed some ability to translate from German to English based on the data, but it is far from perfect. It is though considerably smaller in scale than a production translation network would be.
References:
The original Transformers paper ‘Attention is All You Need’, Vaswani et al. (2017)
The repo for Andrej Karpathy’s nanoGPT
Jay Alammar’s ‘The illustrated transformer’
François Chollet’s book ‘Deep Learning with Python (2nd edition)’
OpenAI’s, ‘Language Models are Few-Shot Learners’
Previous Transformer notes: