
Helix, White City
Transformers 2: The structure of a Transformer
Continuing the series of notes on Transformers I’ll now look at the overall structure of Transformers and how attention is used within them in the context of language translation. I’ll cover:
1. The architecture of Transformers
2. How attention is included in the Transformer
The previous post discussed the attention mechanism that underlies how Transformers work.
1. The architecture of Transformers
1.1 The overall structure
The diagram below is taken from the original paper that introduced Transformers. The Transformer is split
into two blocks: The encoder and the decoder. On the left-hand side is the encoder where the language we want
to translate from is input. On the right-hand side is the decoder which generates the translation. As shown
in the diagram both encoder and decoder contain attention layers.
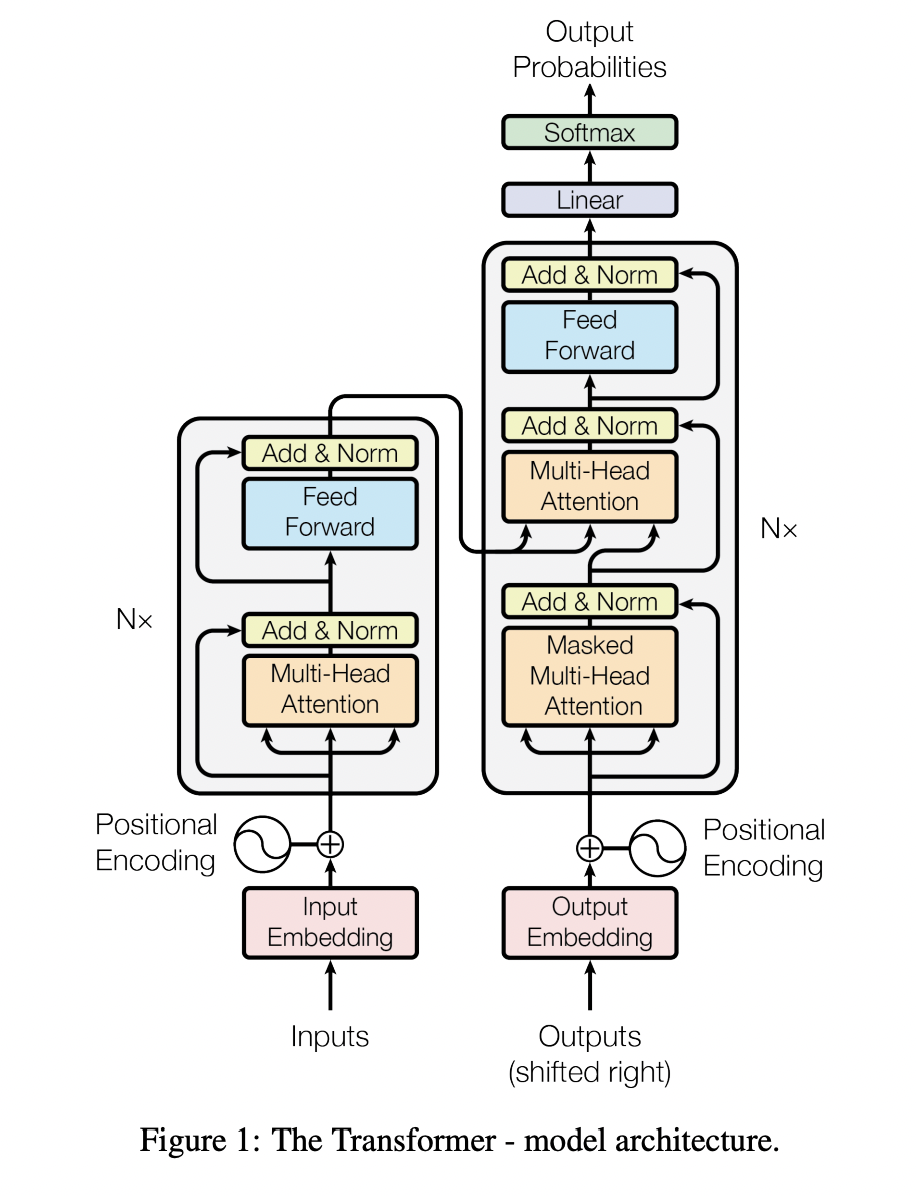 Figure is from ‘Attention is All You Need’, Vaswani et al.(2017)
Figure is from ‘Attention is All You Need’, Vaswani et al.(2017)
To train the model to translate from one language to another, the original text and its corresponding translation are fed into the model at the bottom through the two embedding layers. The original text is processed by the encoder and then combined with results of the decoder to make a prediction of what the translation should be. A softmax layer is used by the decoder to output the probabilities of different words in the language the input text is translated into. The model weights are adjusted in training to minimise the errors that the model makes in translation.
If the Transformer was just focussed on generating text in one language, such as in GPT that answers questions, then the architecture would be simpler - effectively many repeated layers of the encoder followed by the linear and softmax layers.
To generate a translation the Transformer once trained operates recursively. From the input text it is trying to translate it predicts the best word to use for the first word of the translation. It then takes the predicted first word and the input text to predict the second word of the translation. It then takes the first and second predicted words and the input text to produce the third word of the translation and so on.
1.2 The numbers that parameterise the Transformer
Within this overall structure, a few key parameters specify the overall size of a Transformer and are often used to describe them:
1. The dimensionality of the vectors words are converted into in the embedding stage.
2. The dimensionality of the query, key and value vectors in the attention layers.
3. The number of heads in multi-head attention which are calculated in parallel.
4. The number of encoder and decoder layers. This is the number of times the encoder and decoder blocks in the diagram are repeated (The Nx in the diagram).
The query and key vectors need to be the same dimensionality, but the value vector can have a different dimensionality.
2. How Attention is included in the Transformer
Within the Transformer as shown in the diagram there are a number of different features that are combined with the Multi-head attention layers to generate translations.
1. Outputs (Shifted right)
2. The positional encoding which is applied to both the inputs and the outputs
3. The Masked Multi-head attention
4. The Multi-head attention layer in the encoder that receives inputs from the decoder (encoder-decoder attention)
5. The add (the residual connection) and normed layers
We’ll cover these in turn:
2.1 Outputs (shifted right)
In training the text we want to translate from is fed into the encoder and the corresponding translations are
fed into the decoder. In the diagram the translated text is labeled as output text as once trained the
generated translations are the outputs.
 In training, the training text for the language we are translating into has the token [start] added at the
beginning and finishes with the token [end]. The text in the language we are translating from is unchanged.
In training, the training text for the language we are translating into has the token [start] added at the
beginning and finishes with the token [end]. The text in the language we are translating from is unchanged.
For the purposes of the example will translate from German to English. On the training stage the text that is fed into the Encoder are sentences written in German, while at the same time the corresponding sentence translated into English is fed into the Decoder. For example, if we feed in the German text ‘Geh’ then the English text we feed in at the same time is [start] ‘Go’ [end]. The Outputs (shifted right) offset means that when the Transformer receives ‘Geh’ and tries to predict the next word in the translation, then that word is ‘Go’ as the sentence has been shifted right by one token.
2.2 The positional encoding which is applied to both the inputs
As discussed in the first post the words fed into the Transformer are converted into vectors using
embeddings. In addition to the information about the words in the text there is information about their
position in the text. This information can be incorporated by adding a vector of the same dimensionality as
the embedding vector to represents a word’s position in the text it is in.
 In the original Transformers paper this was done using an approach based on sine and cosine functions. An
alternative approach is to train another embedding, that maps the position of the word in the input text (which is
typically a fixed length) into a vector the size of word embedding. This position embedding vector is then added to the word embedding vector to create a new vector
which encodes both the word and its position.
In the original Transformers paper this was done using an approach based on sine and cosine functions. An
alternative approach is to train another embedding, that maps the position of the word in the input text (which is
typically a fixed length) into a vector the size of word embedding. This position embedding vector is then added to the word embedding vector to create a new vector
which encodes both the word and its position.
2.3 The Masked Multi-head attention
Masked Multi-Head attention, which is used in the decoder,is a refinement to how Multi-head attention is
calculated.
 In the encoder attention is calculated, as in the first post, between all the words in the piece of text that is fed in. However, in the decoder a
different approach is used. This is because to generate a translation, the decoder should only have access to the text we want to translate and its own predictions of the words in the translation. It should not have access to
the actual translation. This means that the decoder, when it computes attention for a token/word in the language we want to translate into should only have access to tokens/words that appear before the word/token. If it could
access all the input translated text in training then it could just copy the inputs, but then it would just be memorising the answers rather than learning the language structure. To address this we apply a mask to the data,
which is basically an upper diagonal matrix that sets the values that come after a token to NA, depending on the token’s location i.e. the first token can calculate attention using just itself, the second token can calculate
attention using itself and the first token. The third token can calculate attention using itself, the second and first token etc etc.
In the encoder attention is calculated, as in the first post, between all the words in the piece of text that is fed in. However, in the decoder a
different approach is used. This is because to generate a translation, the decoder should only have access to the text we want to translate and its own predictions of the words in the translation. It should not have access to
the actual translation. This means that the decoder, when it computes attention for a token/word in the language we want to translate into should only have access to tokens/words that appear before the word/token. If it could
access all the input translated text in training then it could just copy the inputs, but then it would just be memorising the answers rather than learning the language structure. To address this we apply a mask to the data,
which is basically an upper diagonal matrix that sets the values that come after a token to NA, depending on the token’s location i.e. the first token can calculate attention using just itself, the second token can calculate
attention using itself and the first token. The third token can calculate attention using itself, the second and first token etc etc.
2.4 The Multi-head attention layer in the decoder that receives inputs from the encoder (encoder-decoder attention)
In a translation transformer we need to switch from one language to the other. This is done in the part of
the Transformer shown below.
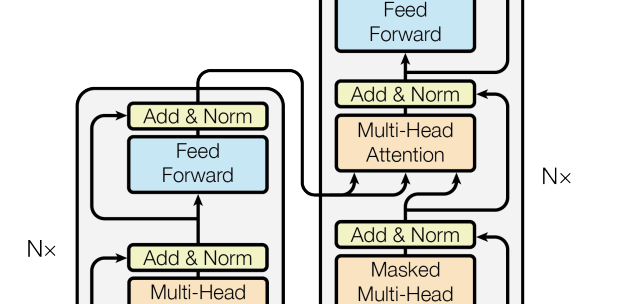 To do this we take the key and value vectors that are generated from the output of the encoder for the language we are
translating from and pass them to the decoder where we calculate the attention of these vectors with the
corresponding query vectors that the decoder generates for the language we are translating into. As here we
are doing a translation from German to English, writing it in matrix form where the indices G and E represent
that the key and values vectors come from German and the query vectors come from English we calculate the
attention as:
To do this we take the key and value vectors that are generated from the output of the encoder for the language we are
translating from and pass them to the decoder where we calculate the attention of these vectors with the
corresponding query vectors that the decoder generates for the language we are translating into. As here we
are doing a translation from German to English, writing it in matrix form where the indices G and E represent
that the key and values vectors come from German and the query vectors come from English we calculate the
attention as: 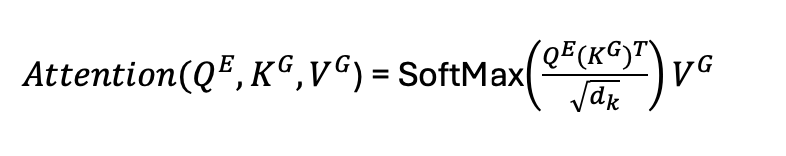
2.5 The add (the residual connection) and norm layer
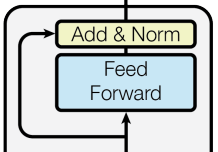
In the diagram below we see the original embedding vector being split up into query, key and value vectors to calculate the multi-head attention. After the attention phase the original embedding vector is also added back into the results of the multi-headed attention and normalised. The addition of the original input is known as a residual connection. It has been found that doing this has made networks easier to train and converge on results. In the normalisation you subtract the mean of the values and divide by the standard deviation. The averaging being done over the elements of the embedding vectors in the batch of text being processed.
Residual connections and normalisation are also implemented in feed forward network. The feed forward
networks transform the outputs of the previous layer into a new set of values, by multiplying by a
weights matrix.

Next steps
Having covered:
- How attention works
- The structure of Transformers
The next post in the series covers implementing a Transformer
References:
The original Transformers paper ‘Attention is All You Need’, Vaswani et al. (2017)
The repo for Andrej Karpathy’s nanoGPT
Jay Alammar’s ‘The illustrated transformer’
François Chollet’s book ‘Deep Learning with Python (2nd edition)’